概述Model Reparameterization: RepVGG 與後續作 (RepOptimizer, QARepVGG, MobileOne)
概述Model Reparameterization: RepVGG 與後續作 (RepOptimizer, QARepVGG, MobileOne)
在電腦視覺 (Computer Vision) 領域上,不論歷經 ViT (Vision Transformer) 如何地挑戰, convolution neural network (CNN) 始終是最受喜愛的架構之一。為了提升 CNN 的效果,近年常用的設計之一就是搭配 residual path 或是多分支 (multi-branch) ,讓 CNN 模型有類似 ensembled model 的行為。
雖然說 residual path 或是 multi-branch 可以讓 CNN 效果提升,但是這樣的架構在許多硬體上執行效率可能是比較差的。 2021 年的RepVGG 提出了一種在訓練時是 multi-branches ,但在推理 (inference)時可以重參數化 (reparameterize) 成 plain model 的架構。讓模型在表現提升的同時,仍然保有 plain CNN model 的運算效率。至今這個方法可以說是已經通過時間的考驗,大量地被許多運算優化的模型使用或進一步改良。
! ([圖片來源](https://unsplash.com/photos/7bzbyafVTYg))")
Tip
文章難度:★★★★☆
閱讀建議: 這篇文章從 CNN 近期發展切入,並簡單介紹 latency 的重要。而後開始介紹近期 model reparameterization 的重要論文 RepVGG,其中會較集中於著墨如何 reparameterize 。最後會再帶幾篇 RepVGG 的後續 follow-ups 研究,包含 RepOptimizer 、 QARepVGG 、 MobileOne 與大量使用 RepVGG 的 YOLOv6 與 YOLOv7 。再最後這個部分,會放比較多的重點再 model quantization 的部分。
推薦背景知識: deep learning, convolution neural network, computer vision, residual network, depth-wise separable convolution, FLOPs, MobileNet, EfficientNet, quantization, quantization aware training.
Convolution Neural Network
這幾年關於應用於電腦視覺 (Computer Vision) 的網路架構研究可以說有兩個主要方向,其一是想方設法把 Transformer [1] 借鏡到 CV 領域,這類方法如ViT (Vision Transformer) [2] 、Swin Transformer [3] 等。另一個方向則是想辦法繼續提升 CNN 的表現,保留其影像上的 inductive bias ,這類方法如ConvNeXt [4] 與RepVGG [5] 等。
事實上,不論歷經 Vision Transformer 如何地挑戰, Convolution neural network (CNN) 至今仍然是深度學習領域最大的要角之一。
有很長一段時間,考慮運算量的模型研究都是依照著 FLOPs (可以直觀理解為四則運算的數量) 在做模型的比較。但實際上
在開發應用時,重要的是 latency 而不是 FLOPs。
這也是為什麼近年許多論文都更關注於不同裝置上實際的 latency。雖然說要討論到不同裝置時,就會很難指出通用的網路設計方法。因為除了不同裝置特性不同外,同類型的裝置也會有不一樣的 roof-line model ,產生一樣的 FLOPs 下,實際 latency 卻天差地遠的情況。
](https://arxiv.org/abs/1910.11609)")
這篇文章不打算針對不同裝置的 latency 深度探討。不過總體上來說有個大概念是:不管在什麼類型的裝置,頻繁的 memory access 通常會對 latency 帶來負面影像(甚至 memory access 通常不算 FLOPs) 。因此,有些為了追求數據上高分的網路,特別是大幅採用多分支 (multi-branches) 的網路架構,在 real-time 應用的部屬上可能反而不見得那麼的好用。
**本篇文章介紹 model reparameterization 主要觀念來自 RepVGG **,是一篇發表於 CVPR 2021 的論文 (“Making VGG-style ConvNets Great Again” )。
RepVGG 的核心概念是一個可以被重新參數化 (reparametrize) 的 convolution 組合。
透過 reparameterization 的技巧,RepVGG 可以訓練時使用 multi-branches 追求最佳效果,在 inference 時再重組成 latency 低的網路,獲得極優秀的 performance latency trade off 。
Reparameterization
顧名思義,所謂的 reparameterization 是把模型參數做一定程度的重組。 RepVGG 雖然不能說是這方面的鼻祖,但卻是最先以結構化的方法,將 multi-branches 的 CNN 進行 reparameterization ,並且刷新SOTA結果的方法。
具體 RepVGG 想法與方法都很單純,因為長期以來 multi-branches network 在預測上都比 plain network 來的好。 RepVGG 的核心精神是設計
訓練時是 multi-branches ,但 inference 時可以 reparameterize 成 plain network 的網路架構。
具體上操作可以分為兩個步驟:
- Folding BN:將 batch normalization 的 (µ, σ, γ, β) 折進 convolution 的 weights & biases 中。
- Reparameterization to plain:**將 3x3 convolution 、 1x1 convolution 與 residual path 合成一個 3x3 convolution **。論文中雖然使用了這三個組合,但其實方法並不限制於特定 kernel size 。
](https://arxiv.org/abs/2101.03697)")
相信大部分人應該對 BN 都已經相當熟悉,但還是先簡單概述一下。Batch normalization [6] (通常簡寫 BN ) 於 2015 年提出,是 deep learning 常使用的技術。特別是在 CNN 設計上,大部分的 convolution 後面都會跟一個 BN。
**BN 主要是在舒緩 Internal Covariate Shift (通常簡稱 ICS ) ,讓模型收斂更有效率的同時,提高泛化能力 。**實際的 BN 是在訓練過程中統計 (µ, σ, γ, β) ,然後對 latent features 進行正規劃。
](https://arxiv.org/abs/1502.03167)")
實作上,接在 convolution 後的 BN ,通常在 inference 時都可以被整合到 convolution 的 weights 與 biases 內:與 deviation 相關的 (σ, γ) 變成 weights 的 scale ,而 (µ, σ, γ, β) 變成 biases。

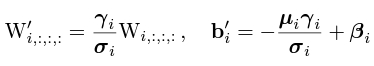
上述式子中並沒有原始的 biases ,這其實也是 CNN 訓練常見的一個通例。當有 BN 時,其實 biases 是 redundant 的,所以通常就直接不使用 biases。
在把 BN 折進 convolution 後,我們可以進一步地把 1x1 convolution 與常用於建立 residual 的 identity path ,也改寫成只有中心有數值的 3x3 convolution。
- 3x3 convolution: 單純把 BN 折進去。
- 1x1 convolution: 把 BN 折進去後,再 padding 成 3x3 convolution 。
- identity path: 把 BN 折進去得到 1x1 的 scales 與 biases ,再 padding 成 3x3 convolution。
](https://arxiv.org/abs/2101.03697)")
接下來就把 kernel weights 與 biases 加總起來,就得到只剩下 convolution 與 activation function 的 plain network。詳細可參考原作者程式碼 。
也許有人會有很直覺的想法:能不能放入更多 branches (像是 ResNeXt builing block),然後一起折進去。雖然 RepVGG 論文中並沒有相關的實驗,不過理論上不論多少個 convolution block 都是可以 reparameterized 成其中一個 kernel 最大的 convolution。其實在MobileOne [7] 中有類似的操作,不過是做在 depthwise convolution上。
RepVGG 實驗數據其實不少,但重點上可以參考以下這張表。總體上,**RepVGG 在比大部分基本的 building block 還要強上一截的同時,連 latency 都是大勝。**下表中 speed 是以 batch size 128 測試在 1080Ti 上,數值為 throughput (examples/second) 。
](https://arxiv.org/abs/2101.03697)")
表中 Wino 指的是一種加速 3x3 convolution 的演算法Winograd [8] ,基本上目前已整合進許多 runtime 中。
*** RepVGG 架構細節不在正文內展開,有興趣可參考 Appendix 1 。
Follow-ups
2021 年發表的 RepVGG ,至今可以說是已經通過時間的考驗,成為一種非常有效率的網路架構。其中**廣泛使用的知名的開源演算法包含 YOLOv6 [9] 與 YOLOv7 [10] 。**同時,**Apple 也將 RepVGG 的概念遷移到 depth-wise convolution 上,發表了在 iPhone 12 上 latency 可低至 1ms 的 MobileOne [7] 。**另一方面,RepVGG 相關的 quantization 問題也是許多人研究的目標,其後續相關重點作品為 RepOptimizer [11] 與 QARepVGG [12] 。
據個人知識所及,目前使用 RepVGG 最知名的兩個模型是美圖的 YOLOv6 與中研院的 YOLOv7 。這兩個框架雖然實作細節差異不小,但在架構上都在網路設計採用 reparameterization 的觀念來進行加速。
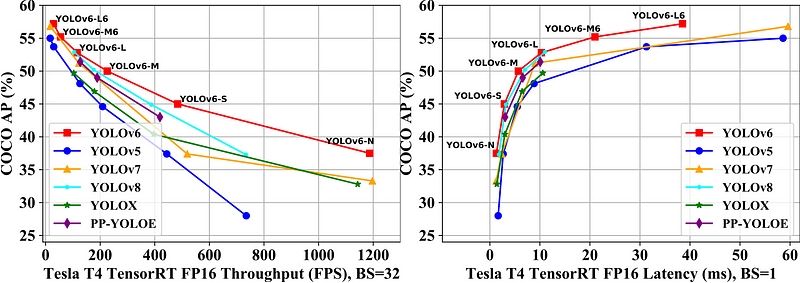
在 YOLOv7 論文裡的數據 v7 是比 v6 還要好,但是 v6 在 2023 年 1 月的3.0 論文 [13] 中做了更新,並且在數據上在反超了 v7 。雖然我並不認為論文的數據就是一切,但還是選擇附上最新的論文數據在此。
另外, YOLO 系列重點其實不算在 reparametrization 上,故不再此細談。
MobileOne 基本上可以說是**延續 ShuffleNetV2 [14] 的 edge 運算優化分析方法,加上 RepVGG 的 model reparameterization ,設計出的 sparse building block。**設計出來的網路可以在 iPhone 12 上以 1ms 的 latency 跑出 75.9% ImageNet top-1 accuracy 。
](https://arxiv.org/abs/2206.04040)")
MobileOne 跑在 iPhone 上會使用到其CoreML [15] 的 NN library 。因為個人˙沒有在 Apple 的晶片實作的經驗,所以也不太確定這邊是否有什麼硬體上的加乘。畢竟過往大部分論文還是跑在 Intel 或是 Qualcomm 的晶片上居多。
MobileOne 的設計其實跟 RepVGG 有點相似,但**設計上基於 depth-wise convolution ,並且導入類似 ResNeXt 的 cardinality **。 building block 由兩個連續的 block 組成,最終 inference 形成類似MobileNet V1 [16] 的架構:
- Multi-branch depth-wise convolution: 類似RepVGG 的 building block ,其中3x3 的一般 convolution 換成 k個 3x3 depth-wise convolution`, 1x1 convolution 換成 1x1 depth-wise convolution。最終 reparametrize 成一個 3x3 depth-wise convolution 。
- Multi-branch point-wise convolution:**即 k 個 1x1 convolution 加上一個 identity branch。**最終 reparametrize 成一個 1x1 point-wise convolution 。
,上半部的 Conv 其實都是 depth-wise 。[(資料來源)](https://arxiv.org/abs/2206.04040)")
論文並沒有強調第一個 block 中是 1x1 depth-wise convolution ,讓我在閱讀的時候相當困惑,因為不知道怎麼把 1x1 convolution 和 3x3 depth-wise convolution 重組成 3x3 depth-wise convolution 。讀了官方 code 才知道是非常特殊地**使用了 1x1 depth-wise convolution ,本質上就是對每個 channel 做 scaling **。
RepOptimizer 是 RepVGG 第一作者後續提出的一種 structure-aware optimizer ,**在已知道某些 prior knowledge 的情況下,可以 reparameterize gradient **。聽起來好像有點難理解,簡單來說這篇論文所說的 prior knowledge 是指像是 RepVGG 這種網路可以後期重參數化的知識,然後利用這個先驗知識,把重參數化的對象變成 gradient 。這個樣訓練出來的網路,論文稱為 RepOpt-VGG 。
結果來看,就是網路不需要先 multi-branch 訓練在 reparametrize 成 plain network ,RepOpt-VGG 一開始就是 plain network ,直接用 RepOptimizer 訓練。
](https://arxiv.org/abs/2205.15242)")
RepOptimizer 論文中有其實一個很大的重點是關於 quantization 的。
Quantization 是網路加速常用的技巧,通常是把運算從 float-32 變成較低精度 (如 int-8) inference 。
在 RepOptimizer 中,作者自己指出了 RepVGG 在進行 PTQ (post training quantization) 後, performance 會掉得比其他網路架構來的嚴重許多(top-1 accuracy從 72.2 掉到了 50.3) 。但如果使用 RepOptimizer 訓練的網路就沒有這個問題。
實際上 RepOptimizer 其實也沒辦法像像是 Adam 這種 optimizer 直接拿來使用。它裡面協助優化的模塊 CSLA (Constant-Scale Linear Addition) 其實**需要設定做 scaling 的向量 s 跟 t (有點像是原本架構裡 BN 在做的事情),但這是個需要被搜出來的超參數。**這也是 RepOptimizer 用起來比較麻煩的地方。
QARepVGG 是 YOLOv6 相關人員出的,更簡單地解決 RepVGG 不適合 quantization 的問題。整體上 QARepVGG 延續 RepOptimizer 的發現,並逐步找出適合 quantization 的 reparameterization 架構。
**QARepVGG 論文認為是合 quantization 的網路需要有良好的 weights 與 activations distribution **,而 RepVGG 中 reparameterized 後的結果是不符合的 (這個 RepOptimizer 其實也有稍微討論到) 。
](https://arxiv.org/abs/2205.15242)")
最終 QARepVGG 細部地分析這個問題,**調整後 PTQ 在 ImageNet 的 top-1 accuracy 下滑量從 21.9 減少到 1.8 **。具體上 QARepVGG 的調整有四項:
- RepVGG 在實作程式碼 中使用了客製化的 L2 regularization,雖然 RepVGG 在 code 的 comment 中說這會幫助到 quantization ,但 QARepVGG 卻指出使用一般的 L2 regularization其實會好很多。
- Identity branch 的 BN 在轉換成 convolution 時,因為 BN 不受 L2 regularization 影響,會造成不適合 quantization 的 weights 分佈。因此再移除 identity branch 的 BN。
- 若 1x1 與 3x3 convolution 的輸出 mean 值相似,就容易產生 variance 變大的情況。因此再移除 1x1 convolution 的 BN。
- 最後因為移除大量 BN ,整體 float32 下的 accuracy 會輸 RepVGG ,因此在branch summation 後加上一個 BN layer。
](https://arxiv.org/abs/2212.01593)")
QARepVGG 的結果雖然有透過分析輔助,但其實還是蠻經驗導向的。**而最後加入的 BN ,也讓 QAT 的訓練可以更加順利,也讓最終 ImageNet 的 top-1 accuracy 可以只掉 0.2。**因此在低運算量模型的實作上, QARepVGG 的價值真的是蠻高的。
個人在 QAT 部分閱讀過程中有遇到一些疑惑,有在YOLOv6 的 Github 中提問 並獲得了解答,也一併附在這邊供參考。
在 RepVGG 發表後的這兩年,許多研究路線與應用的採用證明了 CNN 架構中的 reparameterization 的重要性與好處。在邊緣運算與低運算量的模型設計上, reparameterization 加上 model quantization 可以達到非常巔峰的效果(估計就是 MobileOne 加上 QAT) 。
隨著這些技術的不斷發展和成熟,我們可以期待未來這樣的技術的組合,可以在在電腦視覺領域中更多創新和突破。當然,這裡必定還會有許多研究的推陳出新,包含不同 reparameterized 架構與更簡單進行 reparameterization 與 quantization 的方法都是相當令人期待的。
好了~這篇文章就先到這邊。老話一句,deep learning領域每年都會有大量高質量的論文產出,說真的要跟緊不是一件容易的事。所以我的觀點可能也會存在瑕疵,若有發現什麼錯誤或值得討論的地方,歡迎回覆文章或來信一起討論 :)
Appendix
RepVGG 的網路是由前面所述的 building block (3x3, 1x1, identity) 組成的 backbone。因其網路大小,論文設計 RepVGG-A 與 RepVGG-B 兩個類型。
- 整體把 building block 分為 5 個 stage ,每個 stage 開始用stride=2的 building block 降低解析度。
- 因為第一個 layer 解析度高,而最後一個 layer channels 數多,所以運算量高。因此在該 stage 都只放一個 layer。

- 在 width scaling 時,不同於以往的 compound scaling ,有兩個不同的參數控制深度的 scaling , a 用於前四層, b 用於最後一層,而且設定b> a。因為論文認為最終的 feature 應該要有更豐富的表述能力。
- 因為輸入層 channel 數也不宜太少,因此若a<1時,不 scale down 第一層的 channel 數。

實際上,很多使用 RepVGG 概念的論文 (e.g. YOLOv6) 並沒有使用到他的 backbone ,而是拿他的 building block 堆出更適合自己任務的架構。因此個人認為論文價值跟 EfficientNet 那種 backbone 論文不太一樣,重點還是在 building block。
Reference
- Attention Is All You Need[NIPS 2017]
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale[ICLR 2021]
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows[ICCV 2021]
- A ConvNet for the 2020s[arXiv 2022]
- RepVGG: Making VGG-style ConvNets Great Again[CVPR 2021]
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift[ICML 2015]
- MobileOne: An Improved One millisecond Mobile Backbone[arXiv 2022]
- Fast Algorithms for Convolutional Neural Networks[CVPR 2016]
- YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications[arXiv 2022]
- YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[CVPR 2023]
- Re-parameterizing Your Optimizers rather than Architectures[ICLR 2023]
- Make RepVGG Greater Again: A Quantization-aware Approach[arXiv 2022]
- YOLOv6 v3.0: A Full-Scale Reloading[arXiv 2023]
- ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design[ECCV 2018]
- Core ML[Official Website]
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.[arXiv 2017]