
Sharpness-Aware Minimization (SAM): 簡單有效地追求模型泛化能力
Sharpness-Aware Minimization (SAM): 簡單有效地追求模型泛化能力 在訓練類神經網路模型時,訓練目標是在定義的 loss function 下達到一個極小值 (minima)。然而,在現今的運算資源下, …
Continue ReadingSharpness-Aware Minimization (SAM): 簡單有效地追求模型泛化能力 在訓練類神經網路模型時,訓練目標是在定義的 loss function 下達到一個極小值 (minima)。然而,在現今的運算資源下, …
Continue Reading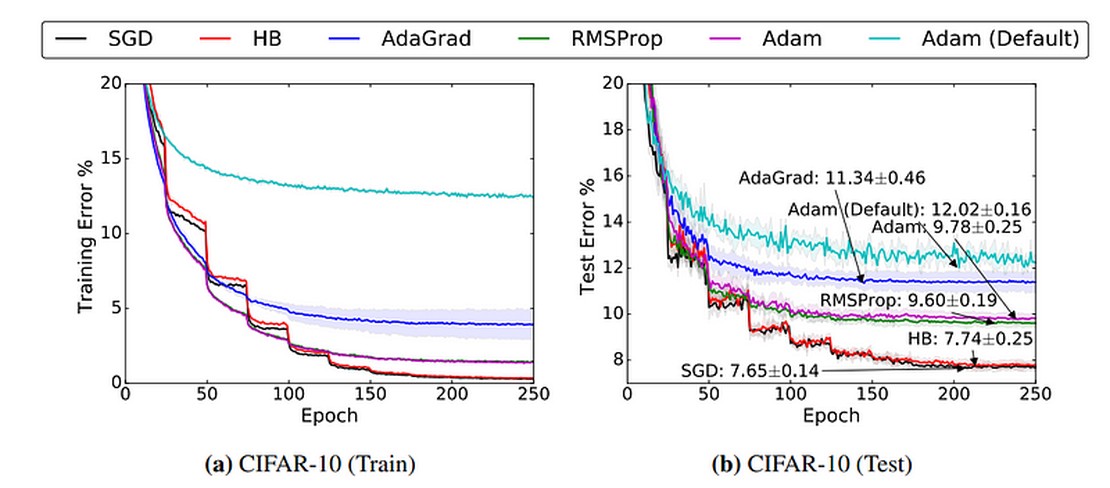
為什麼Adam常常打不過SGD?癥結點與改善方案 對於做deep learning的人,Adam是個令人又愛又恨的優化器。Adam擁有收斂速度快、調參容易的優點,卻也存在時常被人攻擊的泛化性與收斂問題。因此,在許多論文中實驗會使用傳統的SGD+momentum來做分析。但實際上Adam並非不堪用,仍 …
Continue Reading